Sovrn: Efficient Data Delivery
Sovrn provides advertising tools, technologies and services to tens of thousands of content creators. They also offer access to a massive data commons that provides extraordinary insights, helping their customers grow their businesses and increase revenue. The data commons has proven invaluable to content creators, but it requires Sovrn to maintain an identity graph of users, households, and devices in order to provide a consistent experience and view of publishers’ audiences. This involves pulling data from over 40 different systems and linking records by various identifiers across 10 billion records per day. Sovrn tasked Lineate with designing an architecture that processes and stores the data in a fast, reliable, and cost-effective way. Our team was up for the challenge.
Share:
Service:
- Data Integration, Analytics, and Activation
Got a project?
Harness the power of your data with the help of our tailored data-centric expertise.
Contact usShare:
Service:
- Data Integration, Analytics, and Activation
Got a project?
Harness the power of your data with the help of our tailored data-centric expertise.
Contact usProblem
Every second, Sovrn received 115,000 user identifier pairs from various ad tech sources. This inflow created hundreds of terabytes of data that needed to be stored, processed, and used. Sovrn also received files of identifiers (cookie matching, mobile trackers, sets of email hashes) from their partners and needed to match them with billions of records. This approach wasn’t sustainable because every time a file came, they would spin up a fleet of machines to process it. The amount of money needed to process the data was so extensive that Sovrn was beginning to question the profitability of the business line. This challenge was further exacerbated by the requirement of GDPR to delete all traces of a user and all their associated identifiers from the data collected.
Compounding the problem was that 90% of this data was duplicated, and it was more expensive to detect and remove the duplicates than it was to process them.

Solution
Lineate designed and built a graph database on top of HBase that could efficiently filter duplicates and do transitive lookups of identifiers. As a result, the whole connected graph of identifiers for a given user could be inserted and deleted quickly and efficiently.
We began by building a load testing harness and prototyping and testing solutions on a variety of databases, including graph databases (AWS Neptune, TigerGraph, Nebula) and columnar databases (Сassandra, ScyllaDB, HBase). In the end, we chose HBase because of its native integration with AWS S3 (very cost efficient) and its built-in presorting of keys (fast lookups). We patched HBase’s internal compaction logic to optimize for the large volume of continuous writes and parallel batch reads, 24x7.

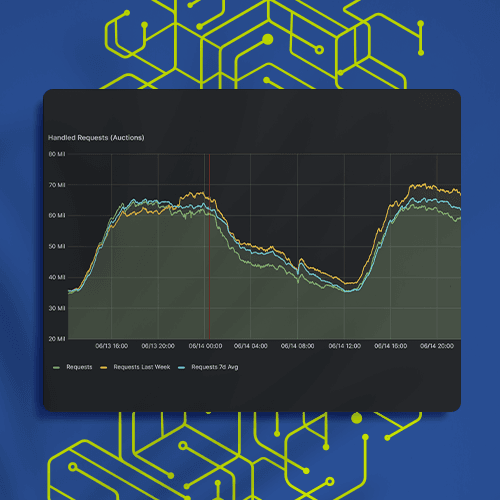
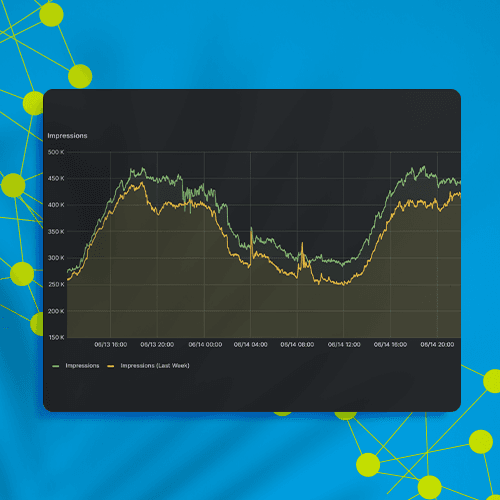

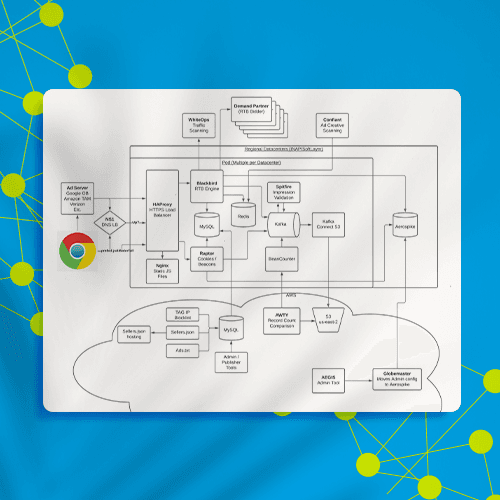
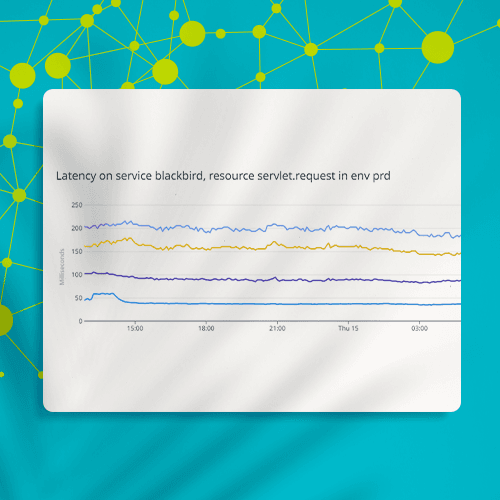
Result
Sovrn’s new system processes 10 billion linked identifiers from 40 different systems on a daily basis. The data are deduplicated automatically during insertion into storage. This efficiency allowed Sovrn to move from storing data from the prior 7 days to storing it from the prior 90 days, and at much lower cost to boot. It also enabled features such as querying or removing a user’s entire graph of identifiers, which was crucial for adhering to GDPR and CCPA requirements.

Tech stack
-
Java
-
Scala
-
Apache Spark
-
AWS Neptune, TigerGraph, Nebula, HBase, ScyllaDB, Amazon Keyspaces
-
AWS EMR, AWS S3, AWS EventBridge, AWS Lambda, AWS SNS, AWS SQS
-
DataDog
-
TerraForm




