
Managing Cold Starts when Going Serverless
The traditional approach to hosting an application typically involves using dedicated servers or virtual machines to run code and serve customers. The transition to serverless computing forces us to decompose the application and change its architecture. With these changes, it is important to consider the specifics of serverless computing early on.
The main component of any serverless computing is the lambda function. The runtime lifecycle of a lambda function consists of three phases:
- an initialization phase, where the execution environment is created and source code is downloaded and prepared for execution.
- an execution phase during which the lambda function is invoked
- a shutdown phase where the execution environment is destroyed
During initialization, when there are no lambdas available to process the next request, a new environment is created for the lambda, which will be able to process this request. This is known as a cold start. The initialization time (or cold start) can take a significant amount of time, which may result in a long delay of as many as several seconds added to the request. This problem is especially relevant for applications where response time is important, and where there are frequent jumps in the number of incoming requests.
There are several approaches to minimizing the impact of this issue on applications on Amazon AWS.
Utilize Interpreted programming languages to write lambda functions
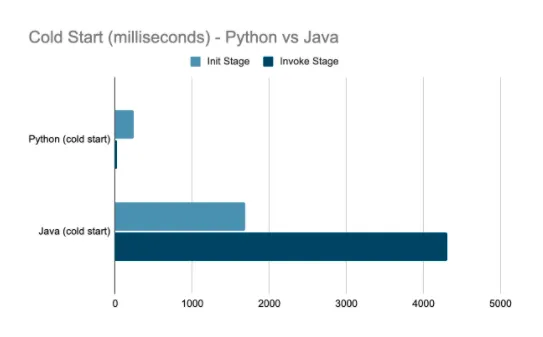
The first way to mitigate a cold start is to use interpreted programming languages like Python or NodeJS to write lambda functions. Interpreted languages avoid the compile-time during initialization that is required for lambda functions written in languages such as Java or C #. Use of interpreted languages in lambda functions allows execution to begin much more quickly in the event of a cold start.
Utilize Provisional Scaling
The second way to mitigate a time-prohibitive cold start is to use a special type of scaling of lambda functions - provisioned scaling. In this way, we fight the frequency of this cold start occurring without affecting the cold start time itself. Provisioned scaling allows you to set the number of instances generated by lambda functions that will always be started and wait for requests from the client. They are already "warmed up" and the request will be processed by already instantiated functions.
Optimize lambda
A third way is rather a group of ways to optimize the lambda functions themselves. For example, part of the initialization phase is downloading the lambda code. We can optimize the amount of code that will be downloaded over the network. For example, for Java, there are frameworks and libraries that allow you to make an application artifact smaller in size. An example of such a framework is Quarkus.We can also decompose our application so that only the necessary code and its dependencies are in the lambda functions. The classic java approach, with a fat jar containing several hundred megabytes, is bad practice here.
Also, to speed up, we can increase the amount of RAM available to the lambda function. Computational performance changes with this change. More vCPUs become available and core frequencies increase. For example, the vCPU of a lambda instance with 128 MB of memory is 2 times weaker than the vCPU of a lambda instance with 256 MB of RAM.
Conclusion
We have considered the cold start problem, why it appears, and what impact it can have on customers. There are many solutions to combat this problem, some are based on reducing this value in numerical terms (fighting the size of the artifact and code base, choosing a suitable programming language), and others help to minimize the number of situations where cold start will be relevant (using advanced cloud provider scaling rules).
Share:
Got a project?
Harness the power of your data with the help of our tailored data-centric expertise.
Contact us