
Experimenting with Generative AI
Lineate recently attended the AI Summit conference in New York. We were inspired to do some experimentation with Generative AI using Optical Character Recognition using AWS Textract and Anthropic’s Claude plugin for Google Sheets. We adapted it to a health care use case to answer the following question: Can Generative AI pull medical information out of free-form medical records that are not designed to be computer readable? The results we found were pretty good.
Medical records are mostly unstructured - and they vary from clinic-to-clinic. But we were able to get accurate information out most of the time without any tuning or prompt engineering. This suggests a modest amount of engineering can get to very high accuracy fairly quickly, far easier than building heuristics to adaptively parse various document formats.
We wanted to try out Amazon Web Service’s Textract to see what it can do with scanned documents. To do this, we wrote a simple application and deployed it to AWS. You can try a demo here. It’s as simple as uploading a file, selecting the biomarkers you are interested in, and clicking “Extract Data.” We uploaded sample medical records and had the application search for various markers. The results were good across a variety of medical record formats, and typically looked like below:
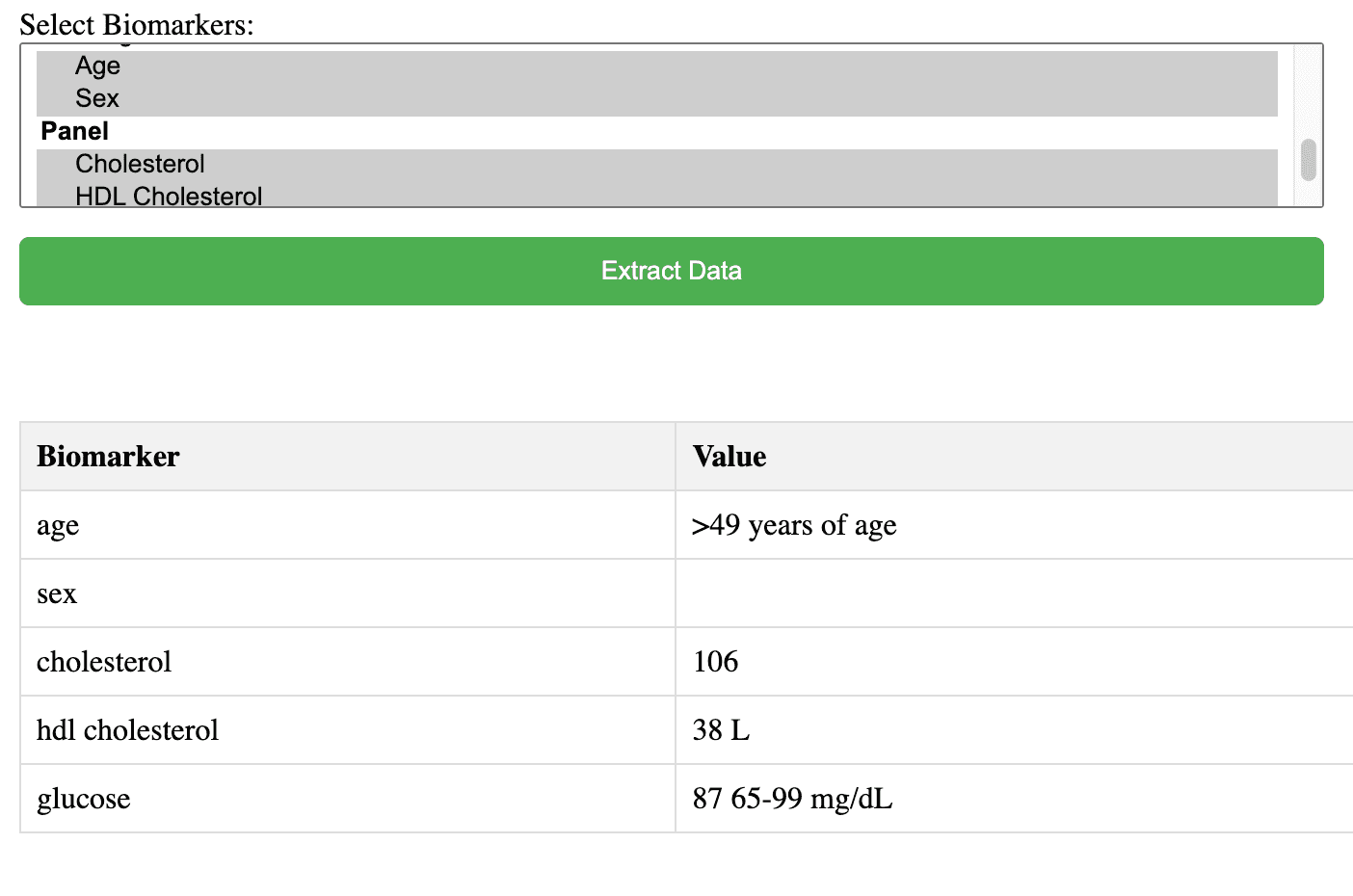
For this record it accurately found and reported on 3 biomarkers, though it also pulled in the standard range of values for glucose. With some tweaks of the prompt we pass to AWS, we were able to properly categorize this information.
We also used Anthropic’s Claude for Google Sheets plug in. We uploaded three PDFs of medical records, scanned them with OCR, and transferred the values into a cell in a Google Sheet. The formulas for the other cells are natural language queries to Claude asking it to pull relevant information from the documents
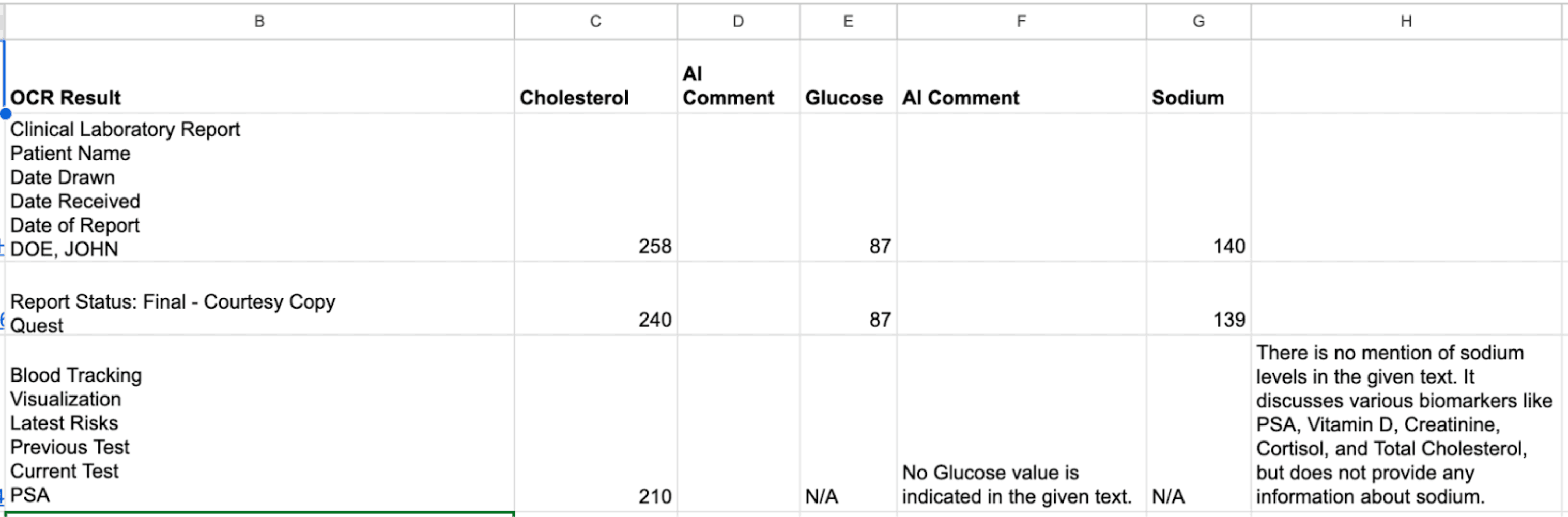
It had no problem pulling the numbers for two reports. We instructed it to output N/A if it didn’t find the information in the document, and to provide a written comment of why it didn’t feel the information was there.
Generative AI is certainly exciting technology, but it’s still not clear what the best use cases will be. This work suggests that parsing data could be a major one. The overall takeaway was that we could very quickly build apps that took in brand new unstructured data and correctly pull the large majority of data points with minimal configuration. With some tuning and prompt engineering, we should be able to achieve a very high success rate across arbitrary document formats.
Share:
Got a project?
Harness the power of your data with the help of our tailored data-centric expertise.
Contact us